
Over 95% of all websites use JavaScript, which is the universal programming language of the web. Websites that we use daily, like Youtube, Facebook, Wikipedia, Twitter, etc., all use Javascript. Our very own Google uses Javascript for both front-end and back-end.
The primary reason behind this is that the pages built with the JS framework are more interactive, be it for menus, pulling in products, or when the primary content is injected into the DOM via Javascript.
It’s becoming a norm for entire websites to be built using popular JS frameworks like React or Angular. These frameworks are used to power mobile and web apps since they can build both single-page and multiple-page web applications.
Another reason for the popularity of Javascript websites is that the content is updated in real-time, which paves the way for its usage in trading platforms where the exchange rates update continuously.
The interactivity Javascript allows websites to have comes with a challenge – SEO.
Let’s just say that Javascript and SEO don’t quickly get along with each other. The reason is that most are oblivious to Javascript SEO – a discipline of technical SEO focused on optimizing websites built with JavaScript to enhance their visibility by search engines.
When we talk about sites built on JavaScript., we’re not referring to websites with a layer of JS to HTML documents or the addition of JS animations to a static web page; we refer to JavaScript-powered websites. Javascript-powered websites are where the core or primary content is injected into the DOM via JavaScript.
A more popular term for the Google-website interaction is crawling. Google doesn’t interact with your content as a user will. It has its unique way of going through your website. Here are a couple of things you need to know about the Google-website interaction:
This means that the only content Googlebot can see is the content available in rendered HTML. Here’s what Googlebot does:
After Googlebot scans each URL in its queue, the crawler executes a GET request using a mobile user-agent, which returns the HTML document. That’s how Google determines what resources are needed to render the page’s core content. This usually indicates that only the static HTML, not any connected CSS or JS files, gets crawled.
This is why Google may postpone the rendering of JavaScript. Unused resources are queued to be handled as computational resources become available via Google Web Rendering Services (WRS).
After JavaScript is performed, Google will index any rendered HTML. Crawling an HTML site is relatively easy for Google. However, it must be rendered before links are extracted when JavaScript is involved.
We have enlisted some best practices you need to follow to ensure that your JavaScript website is crawled and ranked by the search engines:
As mentioned above, it’s evident that to make your website SEO-friendly (so that it’s indexable), Google needs to crawl and render your website’s JavaScript. It all boils down to ensuring that your website can be crawled, rendered, and indexed by Google. There are several steps you can take to make this happen.
It would help to consider the primary content rules associated with meta tags, title tags, image alt attributes, etc.
It would help if you made sure that the titles and descriptions aren’t reused and that the image alt attributes are set (a point that’s often ignored)
You should never block access to resources or .js files. To allow the resources, you want to be indexed to be crawled first, add the following to your robots.txt file:
User-Agent: Googlebot
Allow: .js
Allow: .css
Don’t forget to link to internal pages using the HREF attribute:
<a href=”content-link”>Anchor text</a>
This will help Google to easily find the links and follow them. Don’t use the following for internal links on your website:
Note: Always use static links to help Googlebot discover your web pages.
With JavaScript, there may be a bunch of URLs for the same content. This can lead to content duplication issues. This can be caused by IDs, capitalization, parameters with IDs, etc.
So, there’s a possibility that the following may exist:
Choose one version you want to be indexed and set canonical tags.
SEOs are used for the server-side 301/302 redirects and since JavaScript is typically run client-side, the redirects pass all signals like PageRank. Search for “window.location.href” to find these redirects in the code.
Because JavaScript frameworks are client-side, they can’t throw a server error like a 404. There are various options for error pages:
To ensure that the images you have added within your content or on your website, link the image from the ‘src’ HTML tag:
<img src=”link-to-image.png” />
Lazy loading is handled by various modules, Lazy and Suspense being the most popular ones. When implementing these, you need to beware that you only lazy load images and not the content. If you have implemented lazy loading libraries, you might notice that it uses a ‘data-src’ attribute to store the real image URL and any additional image information, e.g.,
For example:
<img data-src=”link-to-image.png” class=”inline lazyloaded” src=”placeholder-imge.gif”></div>
This will help you enhance your page load speed. You can also exchange the placeholder image for the target image so that <img src> shows the path to the target image.
Ensure that the rendered HTML has all the information you want Google to read.
Use the Search Console URL inspection tool to check whether Google can render your web pages or not.
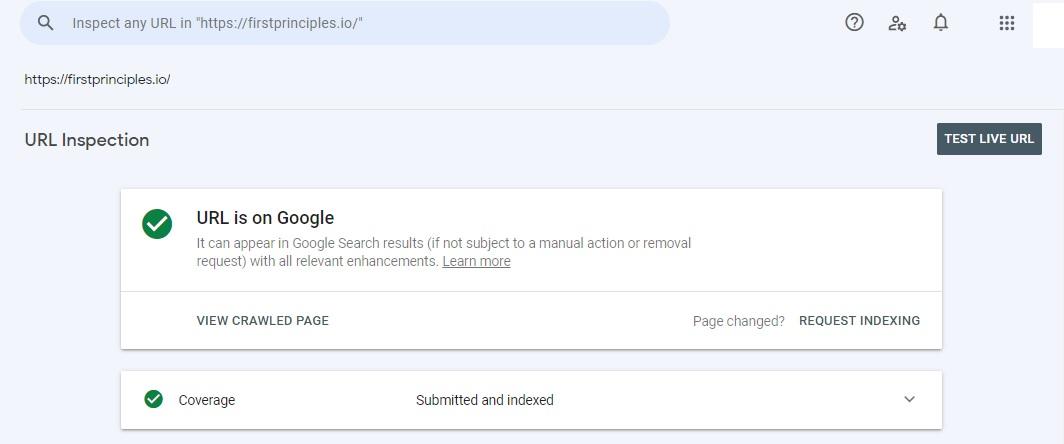
Enter the URL of a page you want to test. Click on the ‘TEST LIVE URL’ button on the top right of your screen.
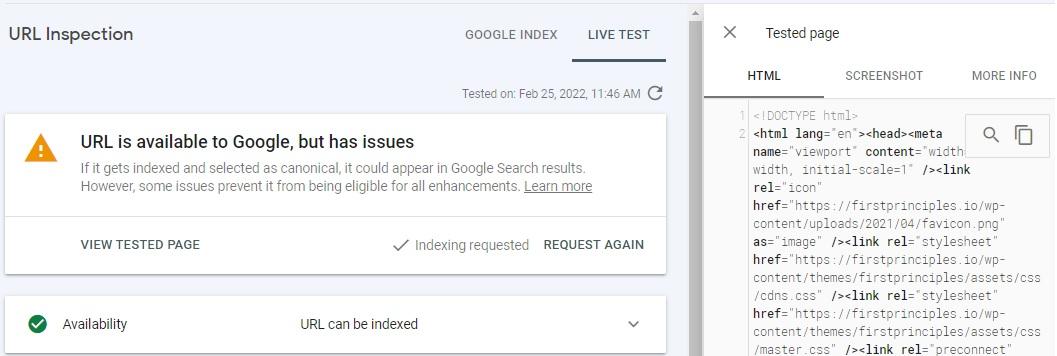
You will soon see a ‘live test’ tab appear, and when you click ‘view tested page,’ you’ll see a screenshot of the page that shows how Google renders it. You can also view the rendered code within the HTML tab.
Keep an eye out for any discrepancies or missing content. Missing content means resources (including JavaScript) are blocked, or errors or timeouts occur. To determine the cause of this error, click the ‘more info’ tab.
Scan the HTML code for snippets of content that you know are generated by JavaScript.
Once your web page is rendering correctly, the next step is to determine whether or not it’s being indexed. You can check it on Google as well as on Google Search Console.
If you’re checking it on Google, type site: domain-name.com/page-URL to see whether your web page is in the index.
If the page is indexed, you’ll see it in the result.
If the URL isn’t there, the page isn’t indexed.
You can also use the Search Console URL inspection tool to check the same.
Click the ‘view tested page’ button and view the indexed page’s HTML source code.
Undoubtedly, using JS can cause crawling and indexing issues for your website’s content. However, by understanding the causes behind these issues and with the tips mentioned above, you can avoid them. Hopefully, this article gave you the confidence to work with Javascript websites.
